
动态规划-算法引入
算法引入
动态规划(英语:Dynamic programming,简称 DP)是一种在数学、管理科学、计算机科学、经济学和生物信息学中使用的,通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。
动态规划常常适用于有重叠子问题和最优子结构性质的问题,动态规划方法所耗时间往往远少于朴素解法。
动态规划背后的基本思想非常简单。大致上,若要解一个给定问题,我们需要解其不同部分(即子问题),再根据子问题的解以得出原问题的解。动态规划往往用于优化递归问题,例如斐波那契数列,如果运用递归的方式来求解会重复计算很多相同的子问题,利用动态规划的思想可以减少计算量。
通常许多子问题非常相似,为此动态规划法试图仅仅解决每个子问题一次,具有天然剪枝的功能,从而减少计算量:一旦某个给定子问题的解已经算出,则将其记忆化存储,以便下次需要同一个子问题解之时直接查表。这种做法在重复子问题的数目关于输入的规模呈指数增长时特别有用。
斐波那契数列
定义为:由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。
暴力递归
依然可以运用动态规划的思想,我们可以得到状态转移方程 :
代码实现就出来了:
1 | def fib(n): |
这样暴力递归其实是效率很低的,画出递归树就可以很明显的看到:
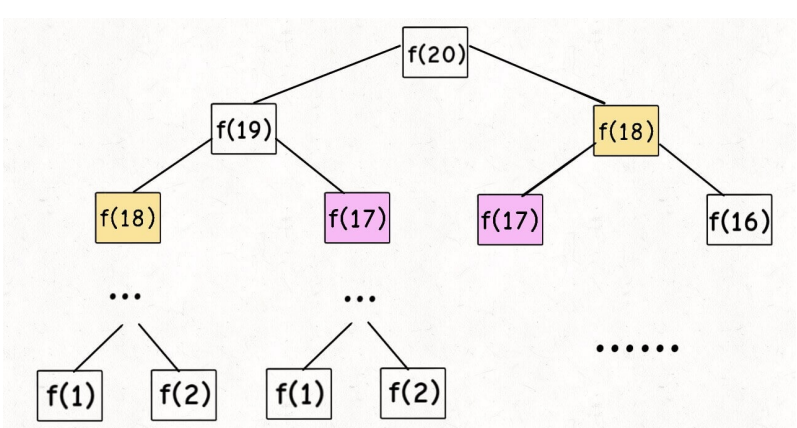
计算f(20)的时候,计算出了f(19)和f(18),到了计算f(19)的时候,又把f(18)计算了一遍,这样重复计算导致效率变低。
备忘录优化
使用一个数组或者字典,将已经计算过的值存进去,就像一个缓存一样,这样就可以减少重复计算。
代码实现如下:
1 | def fib(n, tb: List): |
递归图如下:

这样就将递归树中的冗余计算都去掉了,时间复杂度从O(n^2)优化到了O(n),可以说是降维打击。
根据思考解题的方向可知,这是一种自顶向下的方式,从最终结果也就是递归树的根节点,递归往下计算直至返回,如下图所示:

dp数组自底向上迭代
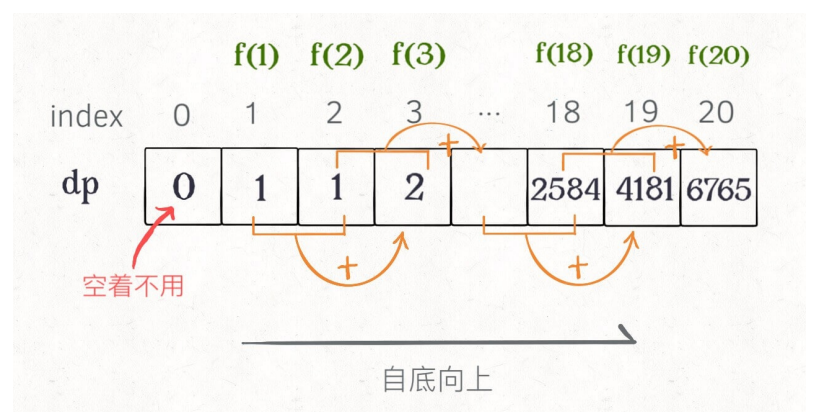
其实我们还可以自底向上的迭代求解,从最小的f(1)和f(2)往上推出f(20),代码实现如下:
1 | def fib(n): |
dp数组空间优化
我们观察到,每一次的结果实际只跟前两次的结果有关,所以可以只存储前两次的结果,对空间进行简化。
1 | def fib(n): |
凑零钱问题
先看下题⽬:给你 k 种⾯值的硬币,⾯值分别为 c1, c2 … ck ,每种硬 币的数量⽆限,再给⼀个总⾦额 amount ,问你最少需要⼏枚硬币凑出这个⾦额,如果不可能凑出,算法返回 -1 。
自顶向下思考
思考步骤:
此问题包含最优子结构的特点,并且子问题之间相互独立,所以是动态规划的问题。
定义正确的dp函数,
dp(amount)=n表示最少需要n个硬币凑出amount金额的钱,这个式子其实也很好列出来,题干中只有amount这一个变量,我们要求解的就是最少的硬币数,设为n,这样就很容易定义出dp函数了。列出状态转移方程:
注意边界条件,如果不能凑出的情况就是当amount比其中最小的硬币面额还要小并且不为0。
代码实现如下:
1 | from typing import List |
画出递归树后可以看到,依然存在冗余的计算,我们可以对此稍作优化,用一个备忘录记录已经计算过的结果,下次用到时,就不需要重复计算了。

优化后的代码:
1 | from typing import List |
这里是用数组当备忘录,实际用字典也是一样。
自底向上思考
一般自顶向下需要用到递归,思路是将最终的问题递归分解为一个一个的子问题,同样我们也可以自底向上计算出结果,从最初的情况向上经历有限次的迭代,最终得到结果。
代码实现:
1 | from typing import List |
方法总结
适用情形:最优子问题,并且子问题互相独立。
思考方向:1.自顶向下递归;2.自底向上有限迭代。
状态转移方程:一般形式为 $dp(变量1,变量2,…)=目标结果$
优化方式:数组或者字典作为备忘录记录中间子问题的结果,避免重复计算。
 wechat
wechat alipay
alipay





